Data Anonymization: Balancing Privacy and Usability
By Jason Vogel, Director, Advisory Services

Data anonymization has become a cornerstone for organizations managing and using sensitive data, particularly in industries such as healthcare and financial services. As legal frameworks like HIPAA and various U.S. privacy laws evolve, anonymization offers a practical solution to protect individual privacy while still enabling valuable data use for processes such as AI model training, third-party partnership data sharing, and general data governance compliance. This article will explore the most popular data anonymization techniques and some legal requirements under U.S. law and provide some scenarios in which a given anonymization technique may be appropriate.
Understanding the Need for Data Anonymization
Data anonymization refers to the process of removing or modifying personally identifiable information (PII) from datasets so that individuals can no longer be directly or indirectly identified. In the context of U.S. privacy laws, anonymization plays a critical role in ensuring compliance with regulations such as the Health Insurance Portability and Accountability Act (HIPAA) and various state-level laws like the California Consumer Privacy Act (CCPA).
HIPAA, in particular, mandates strict privacy protections for an individual’s protected health information (PHI), requiring either anonymization or de-identification of health data before it can be shared for research, analytics, or other purposes. Non-compliance with these laws can result in severe penalties, making anonymization a crucial practice for organizations seeking to balance data utility with privacy obligations.
Anonymization vs De-identification
The goal of both anonymization and de-identification is to protect individuals’ privacy by removing or obfuscating data to prevent being able to identify an individual from the data. The result of these two privacy approaches differs in one major aspect: de-identified data leaves the possibility of re-identification of the data. An example of the usefulness of de-identification can be found when a third party provides customer analytics or market segmentation for a direct marketing campaign. On the other hand, anonymization has the goal of irreversibly altering the data to remove the possibility of re-identification. This approach is appropriate for sharing patient data for medical research or selling data to a third party.
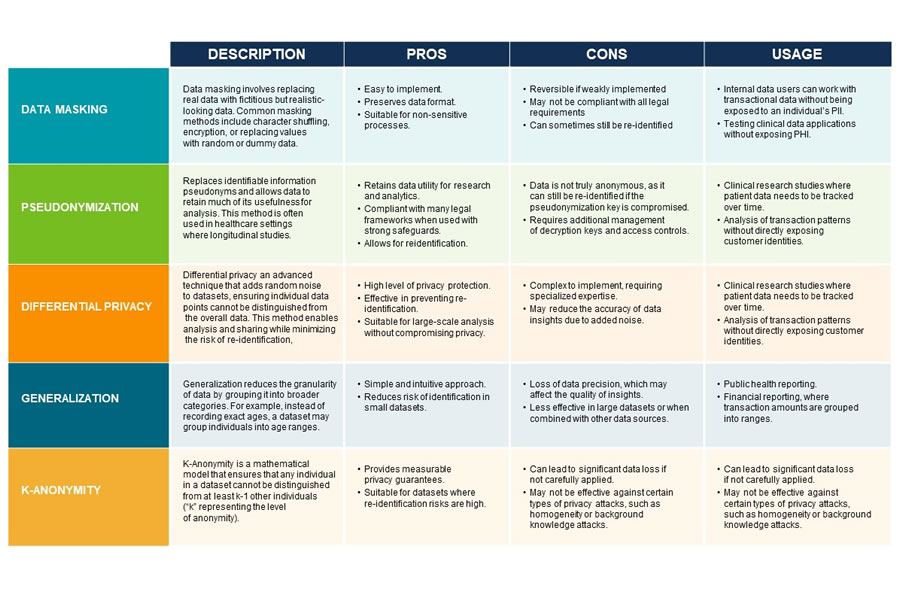
Popular Data Anonymization Methods
Several data anonymization methods are employed across industries, each with unique advantages and drawbacks. The most popular methods include data masking, pseudonymization, differential privacy, generalization, and k-anonymity. Below, we explore these techniques in detail.
Hashing and Tokenization
Hashing and Tokenization are techniques that can be used to obfuscate data, with the primary difference being Tokenization can provide a path to re-identification through access to a data store that contains a cross-reference of the token to the original value (referred to as the “token vault.”) Hashing is a cryptographic technique to reduce data to a fixed length string that cannot be used to reconstitute the original data. Both can be used as techniques to implement the anonymization methods.
Legal Implications of Data Anonymization
Under U.S. privacy laws such as HIPAA and state-level regulations like the CCPA, anonymization is recognized as a key strategy for mitigating privacy risks. However, it is crucial to note that not all anonymization techniques are created equal, and organizations must carefully assess which approach meets legal standards and the specific needs of their use case.
HIPAA and Anonymization: HIPAA allows for two methods of de-identification — the expert determination method and the safe harbor method. The safe harbor method involves the removal of eighteen specific identifiers, while the expert determination method requires an expert to confirm that the risk of re-identification is very small. Organizations must evaluate whether anonymization techniques, such as pseudonymization or generalization, meet these thresholds.
CCPA and Data Anonymization: The CCPA emphasizes the concept of “de-identified” data, which requires businesses to take steps to ensure data cannot reidentify individuals. Like HIPAA requirements, organizations must implement robust anonymization processes to meet these legal requirements.
Conclusion
Data anonymization remains critical for balancing data utility and privacy in industries like healthcare and financial services. While various anonymization techniques offer differing levels of protection, it is essential to choose the right method based on the specific use case and legal requirements. By understanding the pros and cons of each approach and aligning with U.S. privacy laws and HIPAA, organizations can leverage anonymized data while maintaining compliance and protecting individual privacy.





